
Concepto, origen y contexto de las bases de datos.
Desde que el ser humano comenzó a vivir en sociedad, se fue imponiendo la necesidad de los registros de datos, ya fuese para elaborar el censo de una población o para gestionar la economía de una pequeña ciudad de la edad media.
Con el paso de los siglos, esa tendencia se impuso como necesidad en todos los sectores de la vida cotidiana y la evolución de los sistemas de almacenamiento fue imparable, teniendo como objetivo simplificar las labores de almacenado y gestión de los datos.
Así llegamos al ocaso de los ficheros de datos en formato físico, los cuales ocupaban grandes extensiones de superficie y estaban regidos por unos sistemas de acceso bastante precarios, como la búsqueda manual.
Nos topamos entonces con las primeras bases de datos informatizadas, las cuales ofrecían muchas ventajas frente al anticuado modelo físico.
Una de las primeras bases de datos fue la que surgió de la colaboración de IBM con American Airlines, el sistema conocido como SABRE (1960) que permitía gestionar toda la logística y registros de los vuelos de esta empresa.
Una vez expuestos los beneficios del sistema informatizado, fue imparable la migración a este nuevo paradigma, hasta que a día de hoy, el formato de archivo físico es residual y muy poco frecuente.
Ahora para aportar un poco de perspectiva histórica, vale la pena enunciar algunos de los hitos de la cronología de las bases de datos:
En 1970 Edgar Frank Codd definió el modelo relacional de bases de datos, modelo que desde entonces se estableció como referencia dadas sus ventajas y la simplificación que ofrece a nivel de gestión de los datos, tanto a nivel conceptual como de gestión real.
Los apuntes de Codd fueron la base para que el multimillonario Larry Ellison creará la base de datos Oracle, la cual se presenta como el primer sistema gestor de bases de datos informatizados de la historia, este destacaba por sus transacciones, la estabilidad y la escalabilidad del sistema y por el amplio mercado que permitía al ser multiplataforma.
En la misma década, surge un rival para los modelos relaciones, de la mano de Charles Bachman llegan los modelos en red, esto definió un nuevo estándar en los modelos de bases de datos. Sin embargo en 1980 los modelos en red pierden peso en el mercado y se instaura SQL como el estándar dominante, dado que los modelos relacionales se impusieron a las demás (jerárquicas y red).
Las bases de datos fueron ampliando sus posibilidades con el paso de los años y surgieron diferentes clasificaciones en base a ellas, algunas de las características de los gestores de BD son:
En función del modelo de datos
En función del tipo de licencia de uso
En función del número de usuarios:
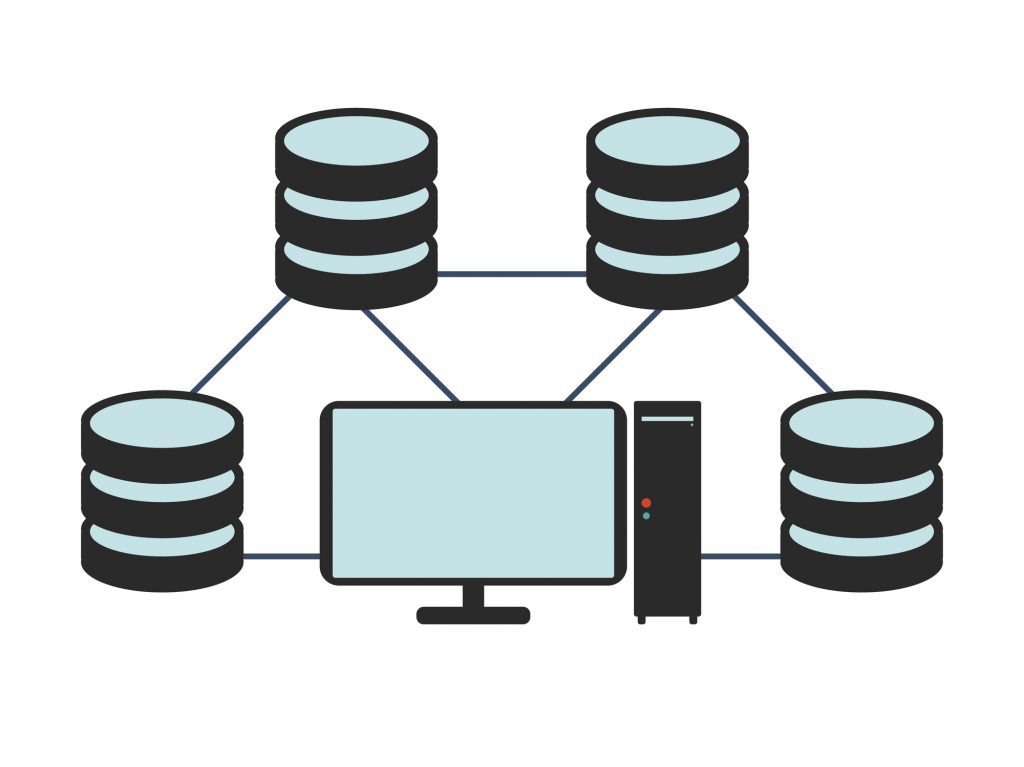
En función de la distribución de sus componentes:
*Los sistemas distribuidos se diferencian entre ellos en base al posicionamiento de los datos y el esquema que ampara esta estructura, existen cuatro opciones principales: